
2025.03.19 - [My project/High Traffic Lab] - 6000만개 데이터 갖고 조회하며 충격받기
6000만개 데이터 갖고 조회하며 충격받기
데이터. 몇개까지 INSERT 해봤나요? (Feat. 대용량 데이터, 데이터 6000만개 INSERT 해보기, Bulk INSERT, Mul대규모 트래픽, 대용량 데이터 처리에 대한 경험을 쌓기 위해 진행한 개인 프로젝트의 시작은 우
te-ho.tistory.com
지난 글에서 대량의 데이터를 갖고 조회를 하는 경우 조회가 현저히 느려지는 것을 경험하고 Index를 사용해서 속도를 개선했다. 이 프로젝트의 최종 모델은 CQRS를 적용했다. 이유는 많은 트래픽, 데이터가 발생하고 존재하는 상황을 가정했기 때문에 어느 시점부터는 Index가 있을 경우 b+ tree를 계속 갱신해야하기 때문에 쓰기 작업 속도를 지연시키는 요소가 될 것이라 판단했기 때문이다.
CQRS로 넘어가기 전에, Index가 정말 쓰기 속도에 영향을 미치는지 눈으로 확인하고 넘어가고 싶었기 때문에 진행했던 테스트 과정을 간단하게 정리하고 넘어가 보겠다!
테스트용 테이블 생성하기
몇 천 개의 데이터, 한 두 개의 인덱스 설정은 체감할 정도의 쓰기 지연이 발생하지 않는다. Mysql / MariaDB는 대학생이 생각하는 것보다 훨씬 강력하기 때문이다. (이 전 게시물 마무리에서 말한 것처럼 웬만한 대학생 수준의 프로젝트에서는 Redis, Pagination은 커녕 Index 조차 없어도 모든 기능이 잘 동작한다..)
이미 존재하는 테이블을 갖고 실험을 할 수도 있지만.. 인덱스 생성하고 시간 측정 / 인덱스 해제하고 시간 측정을 반복하고 싶지 않아 같은 데이터를 갖는 임의의 테이블 2개를 생성하고 하나의 테이블에는 Index를 걸어 정수를 갖는 6개의 컬럼, 인덱스 / 복합 인덱스를 적절히 배치하여 테이블을 만들어주었다.
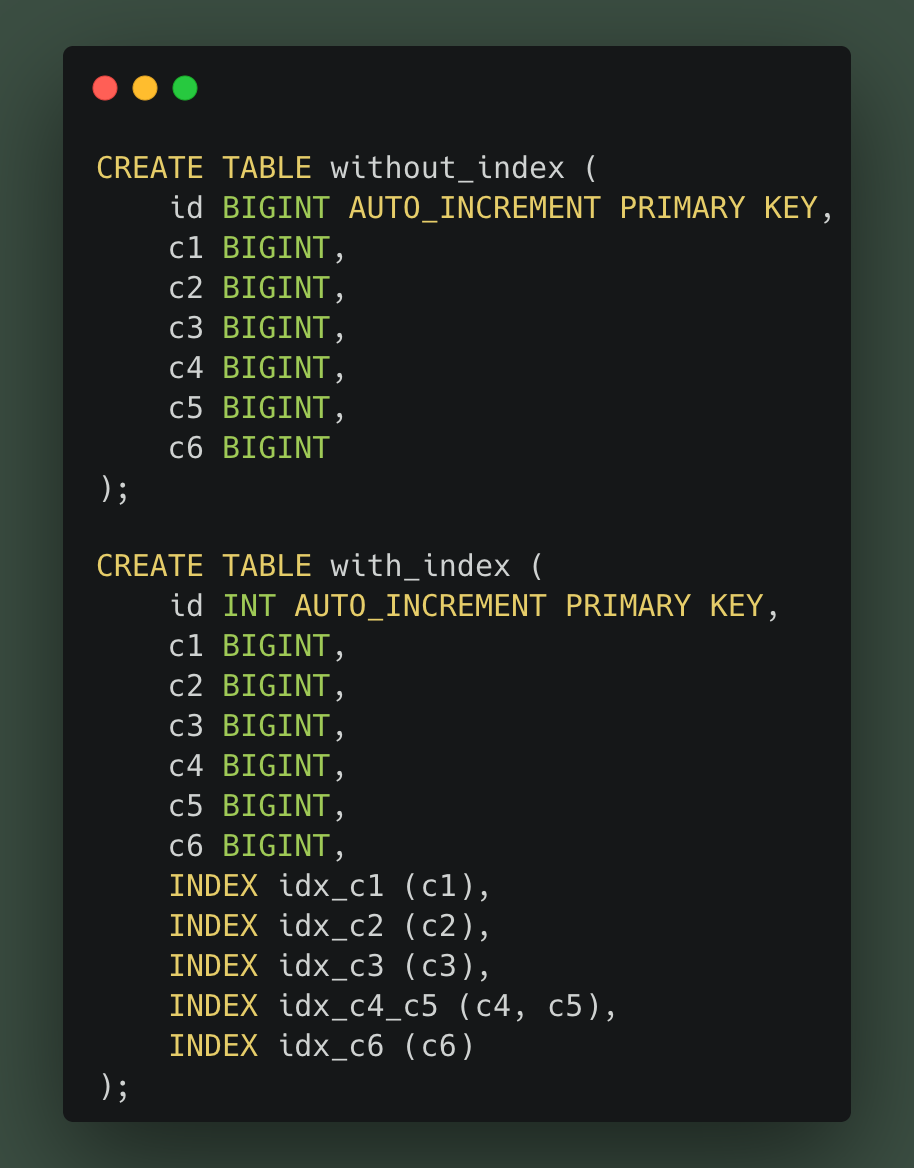
다음으로 대량의 데이터를 생성해줘야 했다. 이전에 6000만개의 데이터를 넣을 때 multi-value insert를 사용했지만 이번에는 굳이 코드를 직접 작성할 필요를 느끼지 못해서 CSV를 생성하여 Import 해주기로 결정했다.
CSV로 대량의 데이터 빠르게 저장하기
Comma Separated Values. CSV는 말 그대로 쉼표로 구분된 값을 갖는 파일이다. 하나의 row를 각 줄에 ,로 구분해 작성하는 형태이며 DB, 엑셀에 모두 호환되어서 데이터를 다룰 때 편리하다! (1, "teho", 26, "대한민국" -> 이런 형식)
csv 파일을 데이터 베이스에 load하면 매우 빠른 속도로 저장할 수 있다. 일반적인 query는 이를 파싱하고, 문법 검사를 해야 하지만 csv는 바로 파일 읽어서 mysql의 데이터 저장 형태인 바이너리로 데이터를 바로 테이블에 저장한다.
나는 shell script를 통해 csv 파일을 자동으로 만들어주었다.
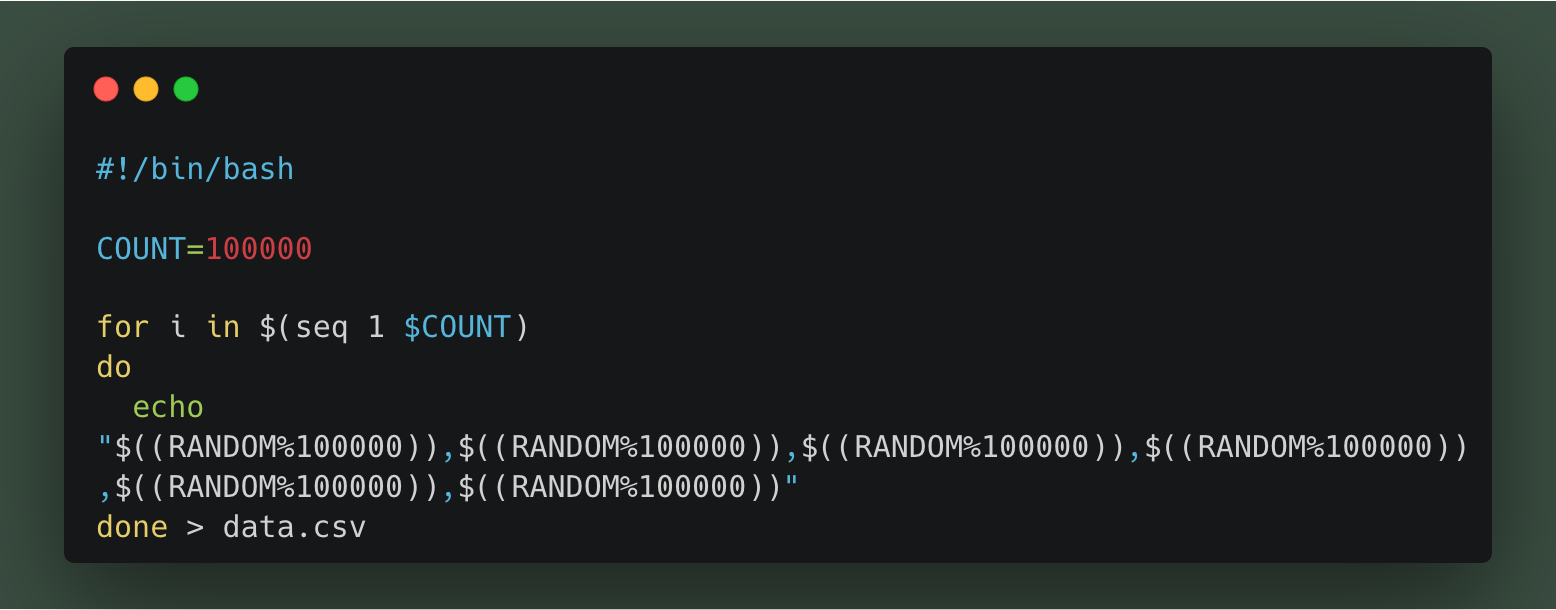
해당 스크립트에 실행권한을 부여하면 다음과 같이 csv 파일이 생성된다. (count를 매우 크게 해 놓고 실행하여 시간이 오래 걸리면 중간에 대충 끊어주었다.)

이제 csv 파일을 DB에 import 해주기만 하면 된다. LOAD DATA INFILE 명령어를 사용해 주면 되는데 주의해야 할 점이 있다. 만약 Docker위에서 DB를 실행시키고 있다면 사용자 입장과 DB입장에서 경로가 다르기 때문에 LOAD DATA LOCAL INFILE을 사용해야 한다. LOCAL에 있는 파일이라는 것을 명시해 주는 것이다. 나는 docker를 사용하고 있기 때문에 다음과 같이 명령어를 사용했다.


시작된 Index의 양날의 검..
위의 명령어를 실행시키면 Index의 파급 효과를 경험할 수 있다. 우선 실행하기 전에 Index가 쓰기 속도에 영향을 미치는 이유는 Index 재정렬 때문이다. B+ Tree 형태로 만들어져 있는 Index를 새로운 데이터가 생길 때 재정렬해줘야 하기 때문에 느려지는 것이다.
나는 1000만개의 데이터를 CSV 파일에 저장했고 이제 두개의 테이블에 같은 CSV 파일을 load 해보면...


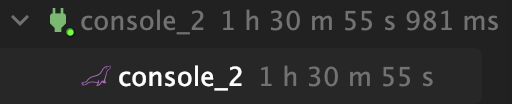


Index가 있는 테이블에 1000만개의 데이터를 저장한 결과 약 1시간 30분이 소요되었다. (실행시키고 운동 갔다 왔다..) Index가 없는 테이블은 약 16초가 필요했고 대략 340배의 차이가 발생한 것이다. 이유는 글의 처음에 작성했듯이 B+ Tree를 알맞게 구성하기 위해 새로운 데이터의 위치를 찾고 트리를 rebalancing 하는 시간이 소요되기 때문이다.
쓰기 관련 API에 미치는 영향
이제는 실제 트래픽이 발생해서 데이터를 새로 Insert 해야 하는 상황에서 속도 차이를 비교해보려 한다. 우선, 더 많은 데이터를 갖고 실험을 하기 위해 CSV 파일을 반복적으로 Load 해주어 각각 6000만개의 데이터를 생성했다. (애초에 CSV 파일에 많은 데이터를 생성하도록 스크립트를 작성하면 되지만 m1 깡통의 버벅거림을 참을 수 없어서 파일 load를 여러 번 하는 방법을 선택했다.

간단하게 데이터를 추가하는 API를 만든 후 단일 요청, 동시 요청을 순서대로 진행해 보았다.

우선, Postman을 사용해 한 번의 조회를 진행하였다. Index가 있는 경우 16ms, 없는 경우 5ms의 결과 값을 보여주었다. 고정 값이 아니기에 각각 30번 정도의 테스트를 진행해 본 결과 Index가 있는 경우 15ms ~ 25ms, 없는 경우 4ms ~ 12ms 안에서 값이 꾸준하게 나왔다.
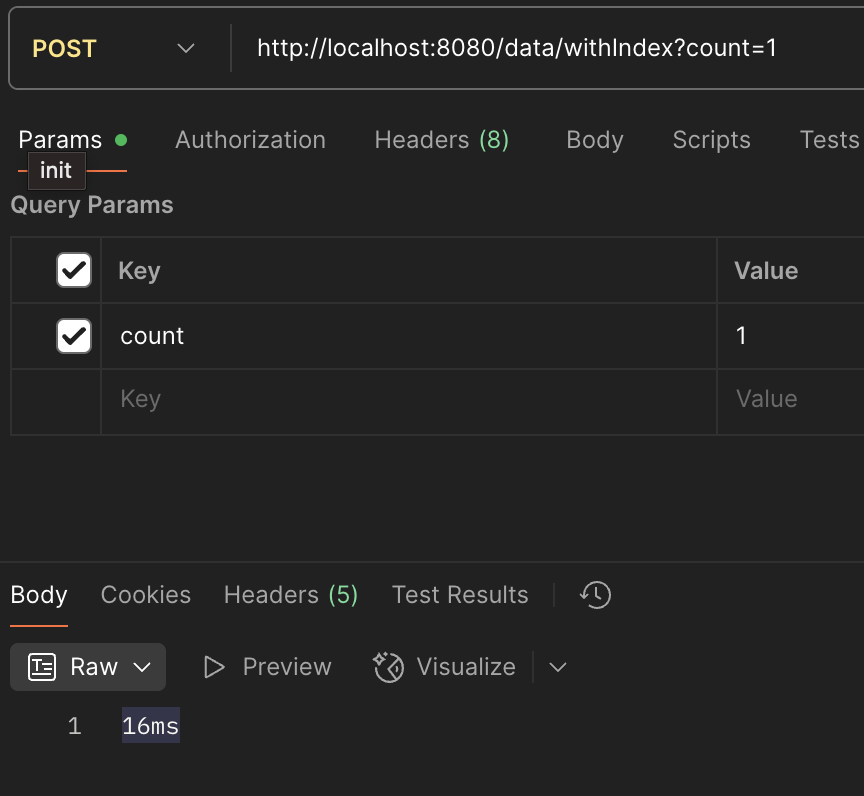

다음으로 Jmeter를 사용해서 1000개의 동시 요청을 발생시켰을 때 Index가 있을 때 평균 1165ms, 없을 경우 262ms의 결과 값이 나왔다.
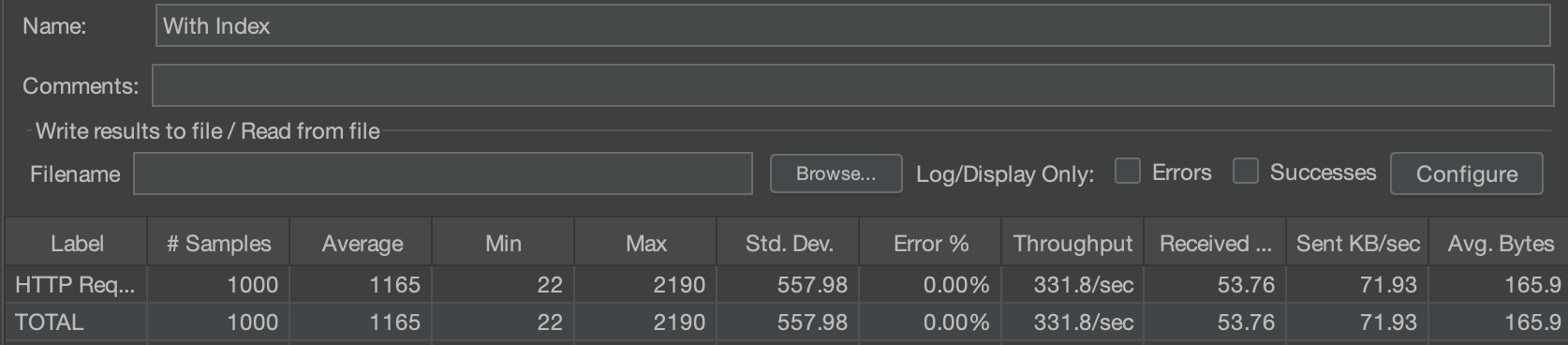
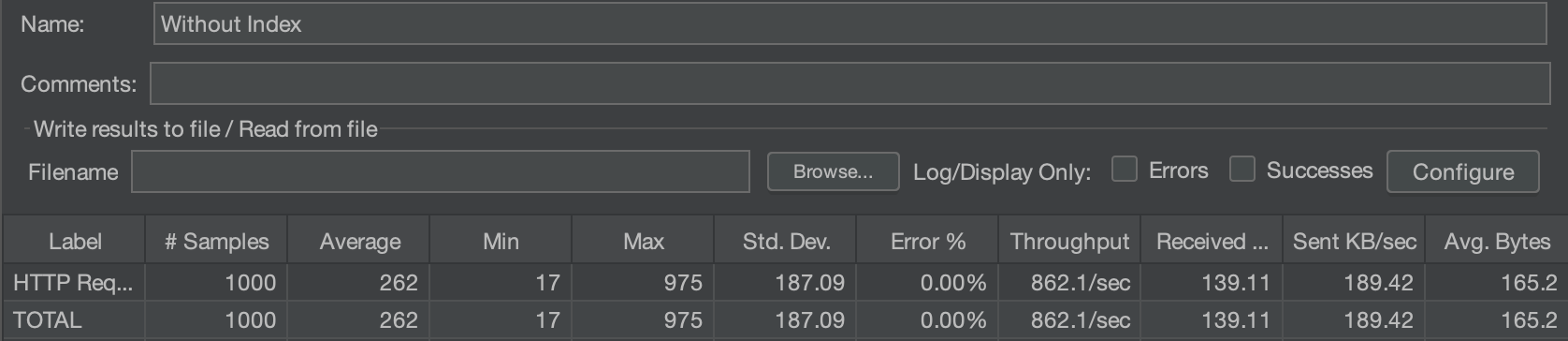
Index가 있는 경우 성능 저하가 있음을 분명하게 확인할 수 있었다.
실제 서비스를 하는 경우에는 다수의 테이블, 연관 관계가 존재하고 내가 만든 구조보다 훨씬 복잡할 것이기에 더 극적인 결과가 발생할 것이다. 또한 DB의 작업 시간이 지연되기 때문에 다른 서비스 로직들에 영향을 미칠 수 있다. 그렇기에 Index로 인한 서비스 전체 성능 저하를 고려해야 할 것 같다.
해결 방법은?
그렇다고 Index를 쓰지 말자! 라는 것은 옳지 않다고 생각한다. 이전 게시물에서 확인했듯이 조회 성능을 별도의 인프라 추가 없이 개선시켜 주기 때문이다. 내가 마주했던 상황에서의 해결 방법을 생각해 보면 아래와 같다.
1. 대량의 데이터를 저장해야 하는 경우
이때는 데이터 저장 전에 Index를 잠시 drop 시킨 후 저장 후에 다시 Index를 거는 방법이 있다. 처음에는 나중에 Index를 다시 설정할 때 오랜 시간이 걸리는 것 아닌가?라는 생각이 들었다. 하지만 이미 데이터가 존재하는 경우, Index에 사용할 컬럼을 기준으로 데이터를 우선 정렬시킨 후에 한 번에 B+ Tree를 생성한다고 한다.
Index가 있는 상태에서 대량의 데이터를 저장하는 경우
1. 데이터를 한 개씩 읽어 Tree에 저장할 적절한 위치 탐색
2. 탐색한 위치에 있는 노드에 저장
3. 해당 노드에 저장할 수 있는 크기를 넘었다면
4. 다시 rebalance 실행..
데이터를 다 저장한 후, Index를 생성하는 경우
1. Index로 사용할 컬럼 기준으로 우선 정렬
2. 정렬된 값들을 기준으로 바로 B+ Tree 생성! -> Leaf 노드를 우선 갖고 Tree 생성 가능 -> Bulk Load
정리하자면 우선 정렬을 하여서 데이터가 들어갈 위치를 탐색하고, tree 구조에 맞게 split, merge 하는 과정이 필요 없는 것이다! 직접 확인해 보기 위해서 1000만개의 데이터를 우선 저장한 후, Index 생성을 해 보았다.

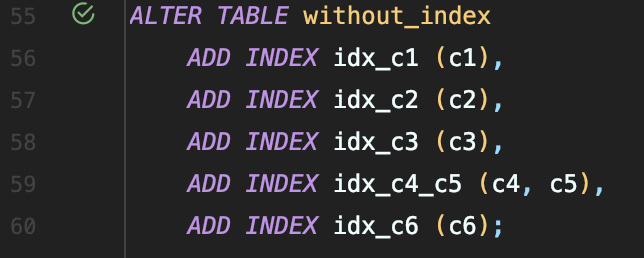
Index를 생성하는데 45초가 소요되었다. 위에서 했던 실험 결과를 참고해서 비교해 보면..
Index 있는 테이블에 데이터 저장 -> 1시간 30분
Index 없는 테이블에 데이터 저장 -> 16초 + 나중에 Index 설정 -> 45초 = 약 1분
압압압압도적으로 후자가 빠르다! 대량의 데이터를 저장해야 하는 경우 잠시 Index를 drop 하는 것은 좋은 선택지라 생각된다.
2. 트래픽이 발생할 때 Index로 인한 서비스 성능 저하
이것의 해결 책으로 CQRS 패턴을 적용했다. 조회 성능이 저하된다는 것은 DB Connection을 점유하는 시간이 길어진다는 것이고, 그 뜻은 다른 요청을 처리하는데 영향을 줄 수 있다는 것이다. 보통 서비스는 조회 요청이 압도적으로 많다고 책에서 봤기 때문에 쓰기 작업으로 인해 읽기 작업이 영향을 받을 수 있는 위험성을 제거하고 싶었다.
마지막 해결책에 대한 내용은 다음 포스트에 작성해보려 한다! 그 과정에서 CQRS의 최종 일관성에 의해 발생할 수 있는 문제들을 고려하느라 머리가 터질 뻔했지만 정말 많은 것을 배우고 나름 경험치를 쌓았다고 생각한다.. 그럼 이만~!
'My project > High Traffic Lab' 카테고리의 다른 글
| CQRS와 함께한 고군분투(Feat. 개발자스럽게(?) 생각하려 노력하기) (2) | 2025.08.21 |
|---|---|
| 6000만개 데이터 갖고 조회하며 충격받기 (1) | 2025.03.19 |
| 데이터. 몇개까지 INSERT 해봤나요? (Feat. 대용량 데이터, 데이터 6000만개 INSERT 해보기, Bulk INSERT, Multi-Value Insert) (0) | 2025.02.23 |
| 주니어 개발자가 대규모 트래픽, 대용량 데이터 경험하는 방법(Feat. 뇌피셜) (1) | 2024.12.16 |