
대규모 트래픽, 대용량 데이터 처리에 대한 경험을 쌓기 위해 진행한 개인 프로젝트의 시작은 우선 많은 데이터를 생성하는 것이었다. 시작부터 고민이 많았는데 "몇 개부터가 대용량이지?", "이전 프로젝트에서 약 1000개의 데이터를 다뤘는데 이것도 많은 거 아닌가??" 이에 대해 조언을 구하고 많은 고민을 통해 결론을 다음과 같이 정하고 계획을 세웠다.
(해당 글은 기술에 대한 자세한 설명보다 해결 과정에 대한 서술에 집중되어 있습니다!)
- 현재 시스템 구조에서 처리가 버거우면(?) 대용량 데이터다.
- 데이터의 양을 점차 증가시켜 조회 성능을 비교해 가며 적절한 양을 찾는다.
이를 토대로 6개의 테이블을 만들고 하나의 테이블 당 1000개부터 시작해서 1000만 개로 크기를 늘려가며 데이터를 INSERT 해보았다. 결과적으로 전체 약 6000만 개의 데이터를 갖고 프로젝트를 시작했다. 이 과정에서 있었던 일을 순차적으로 서술해보려 한다.
(왜 6000만개에서 멈췄냐면 이 이상으로 여러 과정을 진행할 때 나의 깡통 맥북 M1이 버텨주지 못했다.. 마우스 커서 움직이는 것조차 버거웠기 때문이다 허허)

데이터 INSERT는 금방 하겠지~ 라고 착각했다.
INSERT 하는 과정에서부터 많은 과정을 체험해볼 수 있었다. 사실 조회 부분에서부터 고민을 시작할 줄 알았는데 세팅하는 과정에서 여러 시도를 해보았다.
그냥 saveAll() 사용하기
데이터를 집어 넣는 것부터 새로운 경험이었다. 양이 많지 않을 때는 보통 아래와 같은 코드를 사용하면 됐을 것이다.

하지만 이 방법을 사용하면 INSERT 쿼리가 userCount만큼 발생하게 된다. 내 상황에서는 쿼리가 1000만 개 발생하는 것이다. saveAll()을 사용해서 하나의 트랜잭션 안에 넣었지만 쿼리의 양이 너무 많아진다. 실제로 해당 코드의 동작과 동일하게 우선 Item, User의 데이터를 각각 100만 개를 INSERT 했을 때 아래와 같은 결과가 나타났다.



7분 동안 200만개의 INSERT 쿼리 로그가 인텔리제이에 찍히는 모습을 볼 수 있었다. 조금 더 효율적으로 개선하기 위해 다른 방법을 물색해 보았다!
Bulk Insert (Multi-Value Insert)
위에서 시간이 7분이나 걸린 이유는 쿼리가 200만 개가 발생했기 때문이다. 이것을 해결하는 방법은? Multi-Value Insert를 사용해서 하나의 쿼리로 묶는 것이다.
-- 기존의 방법 => 데이터 수만큼 단일 쿼리 발생
INSERT INTO Users VALUES ("user1", "userAGE1");
INSERT INTO Users VALUES ("user2", "userAGE2");
INSERT INTO Users VALUES ("user3", "userAGE3");
-- Multi Value Insert => 하나의 쿼리 발생
INSERT INTO Users VALUES ("user1", "userAGE1"),("user2", "userAGE2"),("user3", "userAGE3");이를 JPA에서 설정을 통해 또는 네이티브 쿼리를 사용해 구현해 낼 수 있지만 jpa 사용 시 별도 설정을 통해 saveAll()의 동작 방식을 아예 변경시키거나, 네이티브 쿼리 사용시 아래와 같이 value 자체를 넣지 못하고 파라미터에 직접 작성해줘야 해서 적절한 방법이 될 수 없다.
@Query(value = "INSERT INTO users (name, age) VALUES (:#{#users[0].name}, :#{#users[0].age}), (:#{#users[1].name}, :#{#users[1].age})", nativeQuery = true)
void bulkInsert(@Param("users") List<User> users);사실 가장 큰 단점은 ID 전략 Auto-Increment를 사용할 수 없다는 것이다. JPA에서 Auto-Increment를 사용하면 ID를 알기 위해 개별 적으로 Insert가 진행된다.
그래서 내가 선택한 방법은 JDBC 레벨에서 Multi-Value Insert를 구현하는 것이다.
JDBC Bulk Insert
JDBC는 java와 RDBMS의 상호 작용에 사용되는 표준 API로 DB에 더 가까운 레벨에서 작업을 할 수 있게 도와준다. 이를 활용해 BulkRepository를 구성한 후 위에서 했던 200만 개 데이터 INSERT를 다시 진행해 보았다.

결과는 매우 성공적이었다! 속도는 7분에서 7초로 약 98%의 속도가 향상되었고, 쿼리는 각 테이블당 1개씩 발생하였다.
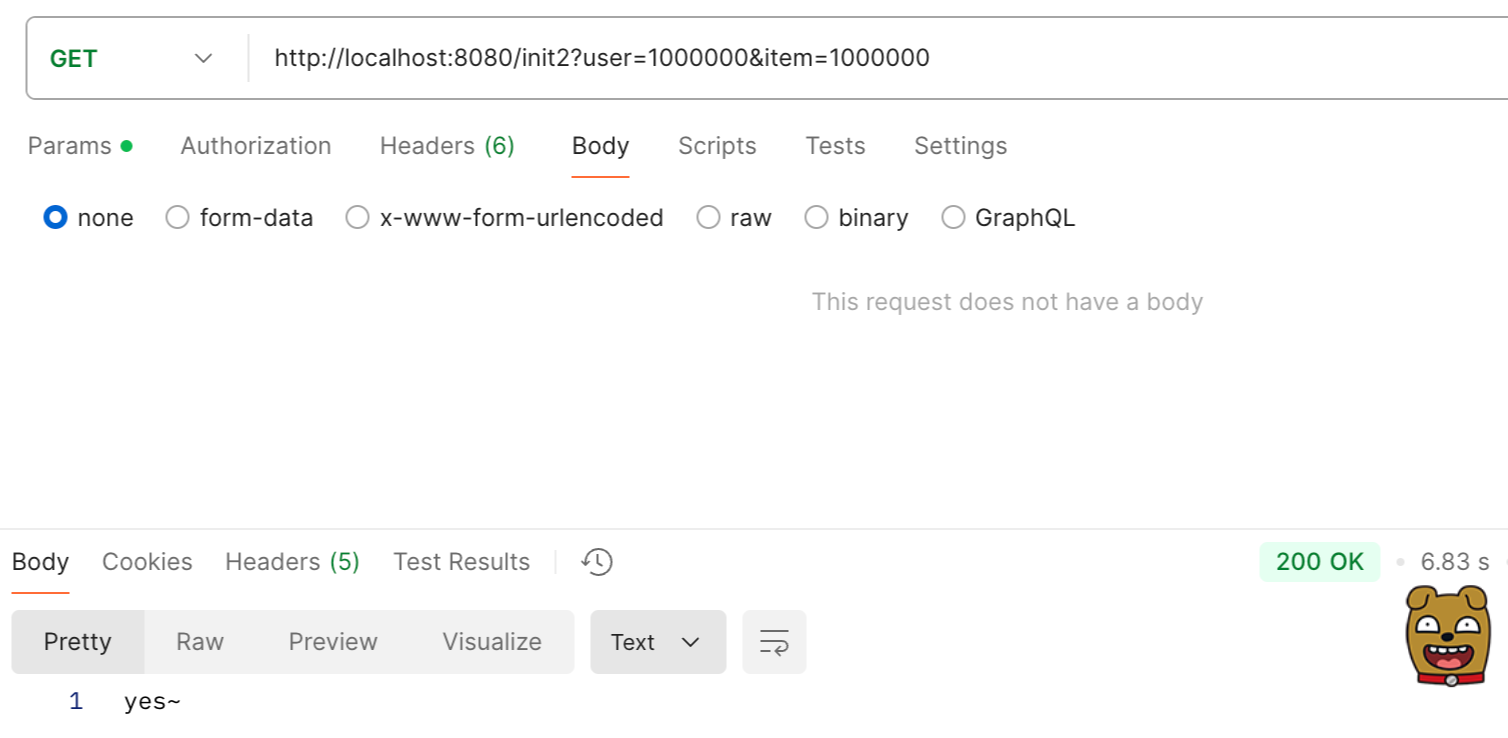

1000만 개로 늘렸을 때 발생한 문제
지금까지의 테스트 과정을 거치고 데이터를 테이블 당 1000만개로 증가시켰다. 이때 전설의 Out Of Memory 문제를 마주하게 되었다. 원인은 Bulk Insert 시 1000만 개의 데이터를 하나의 컬렉션에 한번에 집어넣었고, jdbcTemplate.batchUpdate()에서도 1000만개의 데이터를 저장한다.

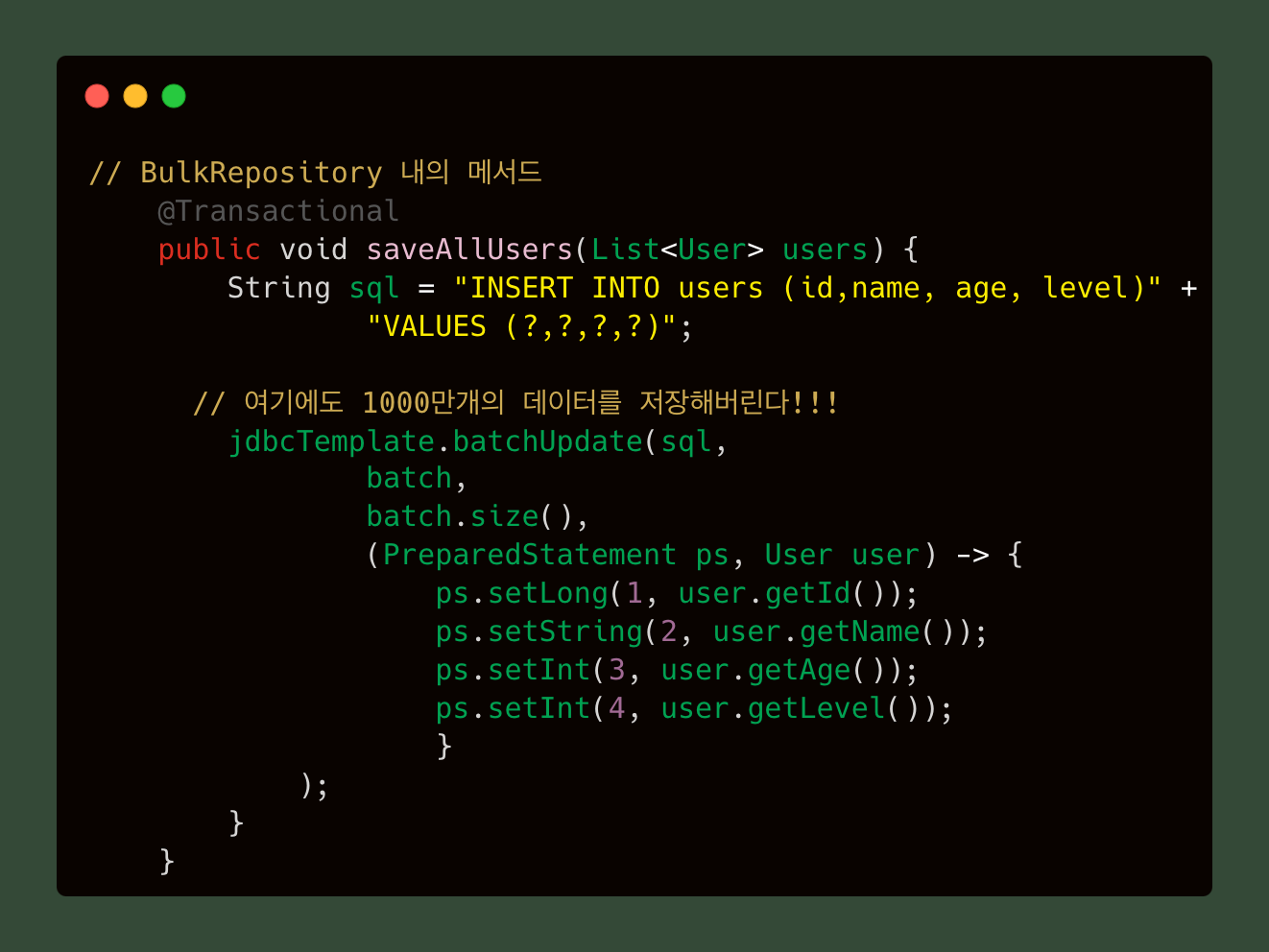
이 코드에서 List<User> users에 1000만 개의 데이터가 들어갔고, 레포지토리에서 jdbcTemplate.batchUpdate()에서 1000만개의 데이터를 저장하기 때문에 JVM의 heap 메모리 영역이 넘쳐 흘러버린 것으로 원인을 파악했다. 해결책으로는 두 개가 생각났는데,
- JVM Heap 메모리 영역 크기 세팅을 늘린다.
- 배치 사이즈를 조절한다.
1번은 너무 성급하게 수직적 확장을 우선 진행한다는 느낌이 들었기 때문에 배치 사이즈 조절을 시도했다. 배치 사이즈를 조절한다는 것은 1000만 개를 한 번에 Multi-Value Insert를 진행하는 것이 아니라, 1만 개씩 1000번 나눠서 진행하도록 하는 것이다. 그렇게 되면 jdbcTemplate.batchUpdate()에 1만 개씩 저장되기 때문에 OOM이 발생하지 않을 것이라 판단했고 최적의 배치 사이즈를 찾기 시작했다.
배치 사이즈를 조금씩 늘려가며 원활하게 동작되는 임계치를 찾아갔고 50만에서 합의(?)를 봤다. 최종적으로 JDBC를 활용한 Multi-Value Insert 코드는 다음과 같다.

주의할 점
앞서 말했듯이 JDBC는 데이터 베이스와 가까운 레벨에서 조작을 하는 것이므로 이런 경우 JPA의 영향을 받지 않아 엔티티가 영속성 컨텍스트에서 관리되지 않는다. 나는 INSERT 외의 다른 과정이 없었기 때문에 상관없었지만 더티 체킹 등을 사용해야하는 경우 주의해야 한다.
다른 방법은?
이 과정을 돌아보며 다른 방법을 찾던 중 엑셀을 활용하는 방법을 알게 되었다. 정확히는 CSV 파일을 사용하는 것인데 엑셀을 사용해서 RDBMS의 테이블 형태로 데이터를 구성한 후 CSV 파일 형식으로 인코딩해서 직접 DB에 넣으면 데이터가 가득한 테이블로 저장이 가능하다! 하지만 나는 코드로 이 문제를 해결하고 싶었기 때문에 프로젝트를 수정하지는 않았다.
돌아보기
프로젝트를 계획하는 과정부터 본격적인 시작을 위한 데이터를 세팅하는 것도 생각보다 쉽게 되지 않았다. 하지만 이 과정을 통해서 save(),saveAll()의 차이를 직접 코드를 뜯어가며 확인해 보는 계기가 되었고, 개별 SQL이 실행될 때 앞뒤로 무슨 일이 일어나는지도 찾아보며 많은 것을 알게 되었다.
궁극적으로 왜 대규모 트래픽/데이터를 처리하는 경험을 요구하는지 몸소 체험하게 되었다. 심지어 이 글에서 있었던 일은 아주 극히 일부분이다.. 이 데이터를 갖고 단순한 조회를 했을 때 걸리는 시간은 정말 신선하게 놀라웠고(조금의 스포) 이 프로젝트를 시작하기 잘했다는 생각과 동시에 앞으로 무슨 일이 벌어질까 하는 두려움과 설렘을 주기 시작했다.
다음 글에서 계속~
2025.03.19 - [My project/High Traffic Lab] - 6000만개 데이터 갖고 조회 해보기 (Feat. Index는 항상 좋을까??)
6000만개 데이터 갖고 조회 해보기 (Feat. Index는 항상 좋을까??)
데이터. 몇개까지 INSERT 해봤나요? (Feat. 대용량 데이터, 데이터 6000만개 INSERT 해보기, Bulk INSERT, Mul대규모 트래픽, 대용량 데이터 처리에 대한 경험을 쌓기 위해 진행한 개인 프로젝트의 시작은 우
te-ho.tistory.com
'My project > High Traffic Lab' 카테고리의 다른 글
| CQRS와 함께한 고군분투(Feat. 개발자스럽게(?) 생각하려 노력하기) (2) | 2025.08.21 |
|---|---|
| MySQL Index 사용 시, 쓰기 성능이 정말 저하되나?? (Feat. CSV로 빠르게 데이터 넣기) (2) | 2025.07.02 |
| 6000만개 데이터 갖고 조회하며 충격받기 (1) | 2025.03.19 |
| 주니어 개발자가 대규모 트래픽, 대용량 데이터 경험하는 방법(Feat. 뇌피셜) (1) | 2024.12.16 |