
검색어 자동완성 구현하기 with Redis (Feat. Elasticsearch)
기획 측 요구사항 지난주 스프린트에 검색어 자동 완성 기능이 있었다. 리뷰를 작성하기 위해 장소를 검색하는 부분인데 사용자가 검색어를 입력하면 해당 검색어가 제목에 포함되어 있는 게시
te-ho.tistory.com
저번 포스트에서 redis를 활용해 검색어 자동 완성 기능을 구현하였다. 이미 redis를 사용해 DataBase의 부하는 줄였지만 신경 쓰이는 부분이 있어서 추가적으로 성능 개선을 해보려 했다.
신경 쓰였던 기존 로직
사용자가 "티 스 토리" 라는 입력을 했을 경우 로직에 따라 원본, 공백 제거, 공백 기준으로 분리하여 키워드를 가공한다.
- "티 스 토리"
- "티스토리"
- "티", "스", "토리"
이 후 미리 redis에 HashMap 형태로 올려 두었던 데이터들의 값을 Map 형태로 모두 가져온 후 key가 각 키워드들을 포함하는지 비교하여 포함한 경우 값을 가져온다. 아래의 경우 초록 색 범위에 있는 key 값들을 가공한 키워드와 비교 연산을 진행한다.

- "티 스 토리" - 일치하는 정보 X
- "티스토리" - 마지막 key(티스토리)와 일치
- "티", "스", "토리" - 티: 티타임, 티수토리, 티스토리 / 스: 스키장, 티스토리 / 토리: 티수토리, 티스토리
연산의 결과 일치한 값의 정보들을 중복을 제거하고 정렬하여 값을 return 해준다. 여기서 내가 생각했던 문제는 아래와 같다.
redis의 key 값 길이 * 가공된 키워드의 수만큼 무조건 비교 연산이 일어난다.
띄어쓰기로 검색어가 길어질 경우 비교해야 할 값도 같이 늘어난다.
선택한 해결책 -> 비동기 처리
단순히 비교 연산을 진행하기 때문에 비동기로 해당 로직을 처리해 보기로 마음먹었다. 개념 설명 글이 아니기 때문에 간단하게 과정과 설명을 작성하겠다.
(비동기, 동기, 멀티 쓰레드, 싱글 쓰레드에 대한 설명은 아래 참고)
멀티스레드? 비동기? (동기, 비동기, 싱글 스레드, 멀티 스레드)
진행하고 있는 프로젝트에서 @Async를 통해 비동기 처리를 하여 성능 개선을 계획 중이다. 관련 공부를 하던 와중에 멀티스레드, 비동기의 차이가 뭐지?라는 질문에 대답을 못하였고 이번 기회에
te-ho.tistory.com
AsyncConfig
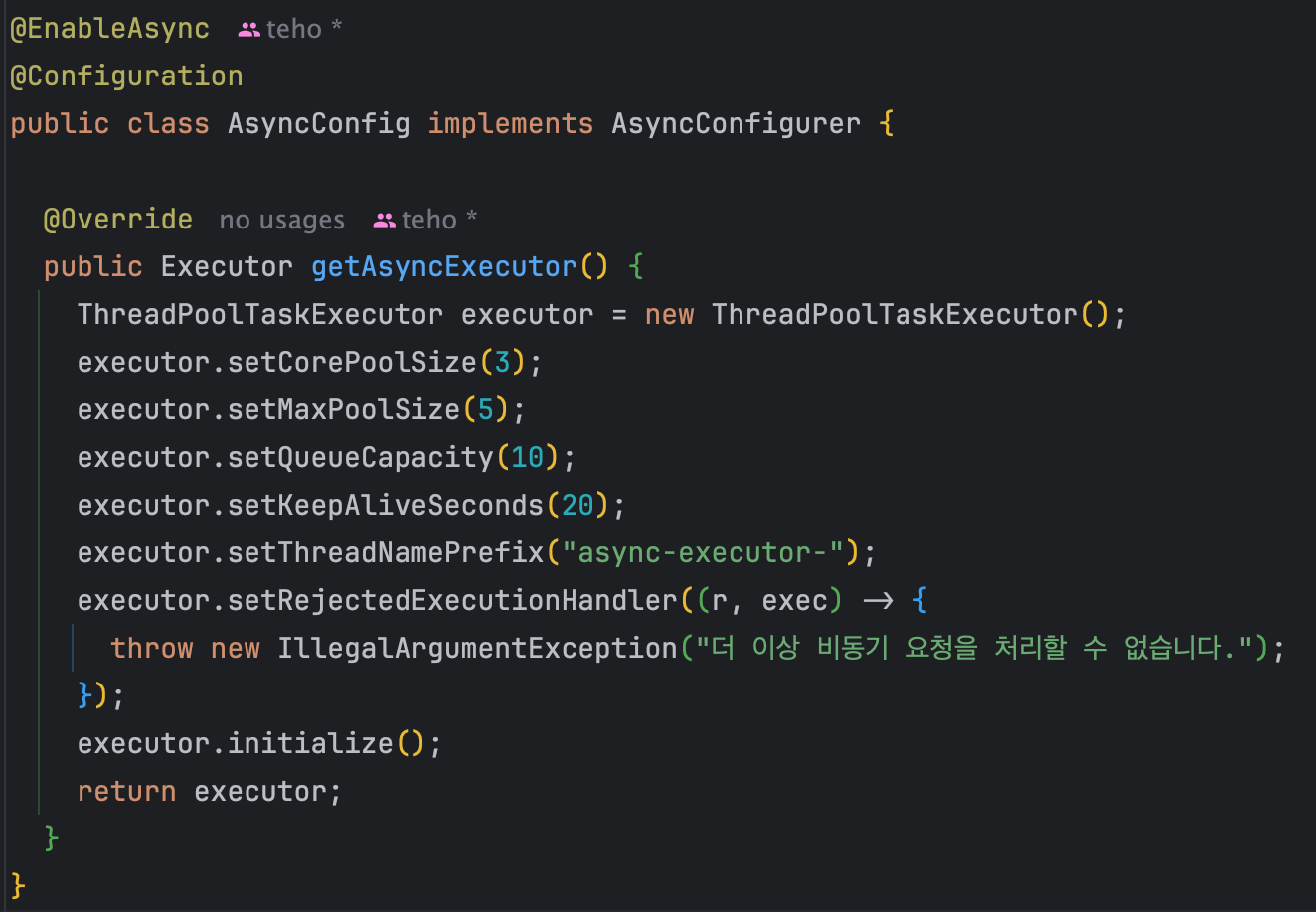
비동기 처리를 하기 위한 환경설정을 해준다.
- setCorePoolSize() : Thread Pool에 항상 존재할 Thread의 수를 지정한다.
- setQueueCapacity() : 모든 Thread가 일을 하고 있을 경우 Task는 Queue에 들어가서 순서를 기다린다. -> 이때 Queue의 크기를 결정한다.
- SetMaxPoolSize() : CorePoolSize에서 정한 Thread가 모두 일하고 있고 Queue가 꽉 찼을 때 Thread Pool이 추가로 Thread를 생성한다. 이때 기존 Thread의 수 + 새로 생성된 Thread의 수를 결정한다. (Thread Pool에 존재할 수 있는 Thread의 최댓값)
- setKeepAliveSeconds() : 새로 생성된 Thread들이 해당 초동안 Task가 없어서 놀고 있으면 삭제된다.
- setThreadNamePrefix : 생성된 Thread들의 이름에 붙일 접두사
- setRejectedExecutionHandler : MaxPoolSize만큼 Thread가 생성되어 일 중이고, queue도 꽉 찼을 경우 발생할 에러.
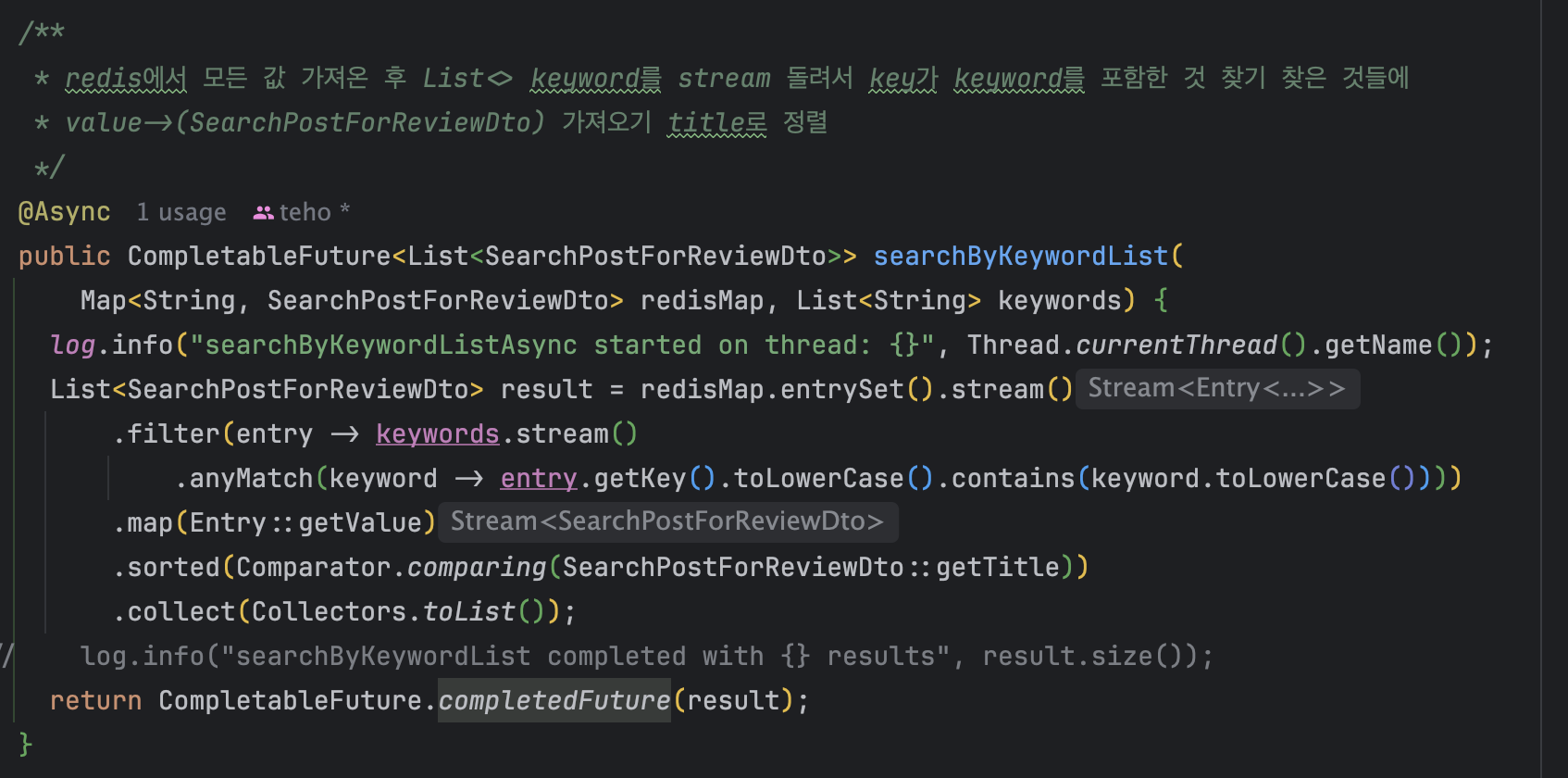
AsyncService & Service
@Async는 프록시 방식으로 동작하기에 클래스 분리하여 로직 작성해 주고 (key들과 검색어 비교하는 코드), CopletableFutre로 반환받는다.


동작 확인
Swagger로 요청하여 비동기로 동작하는 것을 확인하였다.

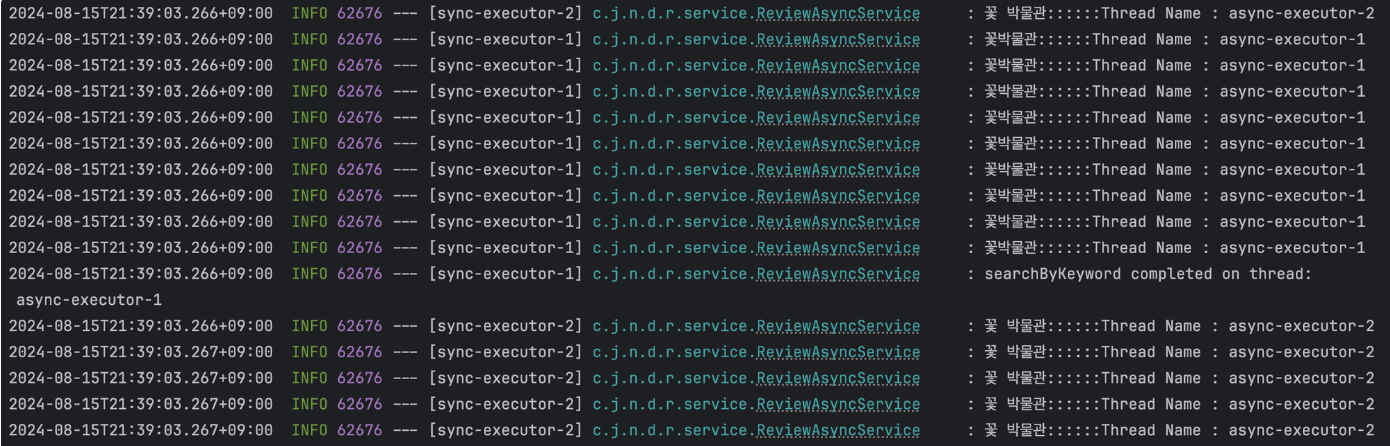
Jmeter로 부하테스트 (현실을 깨닫기 시작..)
성능이 개선되었겠지? 하는 기대감과 함께 Jmeter라는 성능 테스트 툴을 다운 받고 1만 번의 request를 날려보았다.
결론을 바로 말하자면..


위의 결과는 비동기가 49ms 더 빠르다... 하지만 이것도 울면서 몇 번 시도 끝에 비동기가 빠른 경우를 찾은 것이다. thread의 수, queue의 크기 조절 등 여러 방법을 사용했지만 대부분 동기가 미세하게 더 빨랐다. 조금 기운이 빠졌다 열심히 개선했다 생각했는데.. :[
그래도 원인은 알고 싶어서 열심히 찾아보았다.
왜 이 케이스에서는 비동기가 빠르지 않은가?
내가 찾은 가장 큰 원인은 일단 redis에 등록되어 있는 데이터 자체가 많지 않다. (약 500개... ㅎ...) 비교 연산이 너무 많이 일어날까 봐 성능 개선을 해야겠다 생각한 것이지만 컴퓨터는 나처럼 약하지 않았다.. 그깟 500 * 5?6?7? 번의 비교 연산? 컴퓨터에겐 껌이었다..

물론 A==B 정도의 연산까지는 아니지만 그래도 고작 몇 천 번의 비교 연산은 그냥 냅둬도 빠르다.
그렇다면 왜 느린 경우가 더 많았을까???
내가 생각해 낸 결론은 로직을 비교 연산하는 비용보다 비동기 처리 중 Thread 컨텍스트 스위칭에서 일어나는 비용이 더 크기 때문이다.
즉 OverEngineering을 한 것이다. -> 이런 상황에서는 비동기 처리를 하는 것은 적절하지 않았다.
비동기 처리는 언제 하면 좋을까?
비동기를 공부해 본 김에 사용하면 좋은 구체적인 상황을 찾아보았다.
- 파일 I/O : 용량이 큰 파일들을 읽고 쓰고 할 때는 시간이 확실하게 오래 걸린다.
- 이미지 10개 업로드와 다른 동작을 동시에 수행했을 때 이미지 1개만 올리는데도 시간이 적지 않게 걸리는데 1개,,,, 1개,,,, 1개,,,, 1개,,, 순차적으로 올라가면 10개 올라가는 시간도 길고 그동안 추가적인 행동은 이루어질 수 없다. 이때 이미지 업로드 로직을 비동기 처리할 수 있다.
- 외부 API : 외부 API를 요청하는 경우 시간이 유독 오래 걸리는 경험을 해본 적이 있다. 이때도 비동기 처리를 하여 시간을 단축시킬 수 있다.
- 나도 저번 프로젝트에서 ChatGpt API를 사용하였는데 응답을 받아오는데 시간이 오래 걸렸던 기억이 있다. 이때 비동기 처리를 하면 시간을 단축시킬 수 있었을 것 같다.
이 외에도 인터넷에 여러 케이스가 있지만 와닿는 예시는 위의 두 개 정도인 것 같다.
비록 리팩토링한 부분은 폐기되었지만 얻어가는 게 많은 시간이었다. 비동기처리도 해보고~ jmeter도 써보고~ jvm warm up도 공부하게 되고~(다음 포스트 예정)
이만큼 성능이 개선되었어요! 라고 팀원들한테 자랑하지 못하게 된 것이 아쉬우니 귀여운 복슬이 보며 마무리~

'My project > Nanaland in Jeju' 카테고리의 다른 글
| 이미지 조회 속도 개선 (Feat. CDN, AWS CloudFront, S3만 사용하다가 cloudfront 적용하려면?) (11) | 2024.10.19 |
|---|---|
| 프로젝트 진행 시 엑셀에 작성한 데이터, DB에 저장하는 방법 (0) | 2024.10.17 |
| 검색어 자동완성 구현하기 with Redis (Feat. Elasticsearch) (3) | 2024.08.01 |
| Stream API 사용 중 .toList()에서 UnsupportedOperationException 발생한 썰 (1) | 2024.07.26 |
| QueryDsl 부모에 자식 리스트 넣기 -> Transform (부제 : 쿼리의 수와 속도는 무조건 정비례가 아니다..) (0) | 2024.06.27 |